This afternoon I decided to try Yours.org, a site where you can write articles, decide what to charge for them, and get paid in bitcoin cash. I had an idea: If you pay and then a section is revealed to you, that doesn’t have to be just for articles. It can be used for anything digital!
A few ideas:
Podcasts
Photo filter packs for Lightroom
Digital art
eBooks
Word and Powerpoint templates
Photoshop and Illustrator files
Music
Videos
WordPress themes
So, I decided to test it out. I packaged up four sets of national parks photos, put a thumbnail grid in the preview, and put a download link in the paid section:
In just a few hours I made over $40 in bitcoin cash! It is super exciting seeing the notifications come in while you are reading other articles. I think that the notifications are tied to transaction verifications because they come in waves. That must be when blocks get processed and transactions verified.
At Praxis we use Restrict Content Pro as the membership system for our curriculum portal. We decided that all grads get access for life, not just during the program. So, I needed a way to clear over 200 member expiration dates. The only bulk method available through the WordPress interface is to set the expiration dates to another date in the future, which would just kick my problem further down the road. So I needed to dust off my SQL knowledge and directly edit the database.
Step 1: Back up the database.
Don’t be a fool. Back up your database and test the queries on a local development version first. Never run queries for the first time on production. The backup is also a failsafe that you can restore if something goes wrong despite your testing.
Step 2: Find the data.
I saw that all data related to Restrict Content Pro usually had rcp somewhere in the table, column, or key. So I started with the rcp tables. They had nothing to do with expiration dates, so I checked the wp_usermeta table since RCP extends the WordPress users with more functionality. Bingo. There was a column called meta_key with rcp_expiration in it with corresponding date values.
Step 3: Make sure you are editing the correct data by running a SELECT statement first.
Sure, you could run your UPDATE statement first, but I like to make sure I am editing the correct data by running a SELECT statement first and then using the same WHERE clause for my UPDATE statement.
After a few stupid syntax errors, here is the SELECT statement that got exactly what I wanted. This shows the user ID so I can spot check, restricts searching to the rcp_expiration meta key, and looks for values that are not none.
This returned 176 results. When I changed it to show only meta values that were none, I got 31 values. 31+176=207, which is the total number of users. Looking good.
Step 4: Craft your UPDATE statement.
Now that we know we selected the correct data with our previous statement, it is time to craft our UPDATE statement.
Here I’m updating the wp_usermeta table and setting the meta_value to none where the meta_key is rcp_expiration and the corresponding meta_value is not none.
I tested this on my local machine and it updated 176 rows. Just like we wanted.
Step 5: Run the same query on production.
Now that we’ve tested the query in our development environment and verified that we got the results we wanted, we can run the query on the production database. If you use phpmyadmin and want to triple check that you aren’t messing anything up, you can click the “Simulate Query” button first. (I did.)
Step 6: Verify things worked.
Log in to WordPress and check the RCP membership area. Verify that all expiration dates are now set to none. Also verify that your users can still log in. You should have a few user test logins specifically for this purpose. You can also check your site logs throughout the day to make sure people are still logging in. You can’t count on them always letting you know when something doesn’t work. More often than not they will just stop using it. It is up to you to verify everything works as it should!
Adding dates is tricky. Months have different numbers of days, so you can’t rely on just adding 30 days to get an extra month. You also can’t just add a certain number of months because formulas in Salesforce don’t auto increment the year. The solution is modular arithmetic and conditionals.
The goal here was to make a set of fields to send out emails on the first day of each month for 6 months, given a specific month to start with.
What I’m doing here is:
Year: Figuring out the month number, adding one less than the number of months over all, dividing it by 12, and rounding down to add either a 0 or 1 to the year. You have to subtract one from the month because 12/12 = 1 and you don’t want December adding an extra year.
Month: If the resulting month is December, return 12. Otherwise return the month number modulo 12. (12 mod 12 is 0, hence the conditional).
Day: Always returning 01, the first day of the month.
DATE( YEAR( date ) + FLOOR( ( MONTH ( date ) + number_of_months - 1 ) / 12 ), IF( MONTH ( date ) + number_of_months = 12, 12, MOD( MONTH ( date ) + number_of_months, 12 )), 01 )
How to use this: the date variable should be the date field you are starting with. You should replace number_of_months with the number of months you want to add to the original date. If the date is 07/01/2017 I want this to go out on 08/01/2017, I’d set number_of_months to 1. If 09/01/2017, I’d set it to 2, etc.
Note: This only works for the first of each month. If you need it to work on any day of the month, use this more complicated solution to account for months having different lengths.
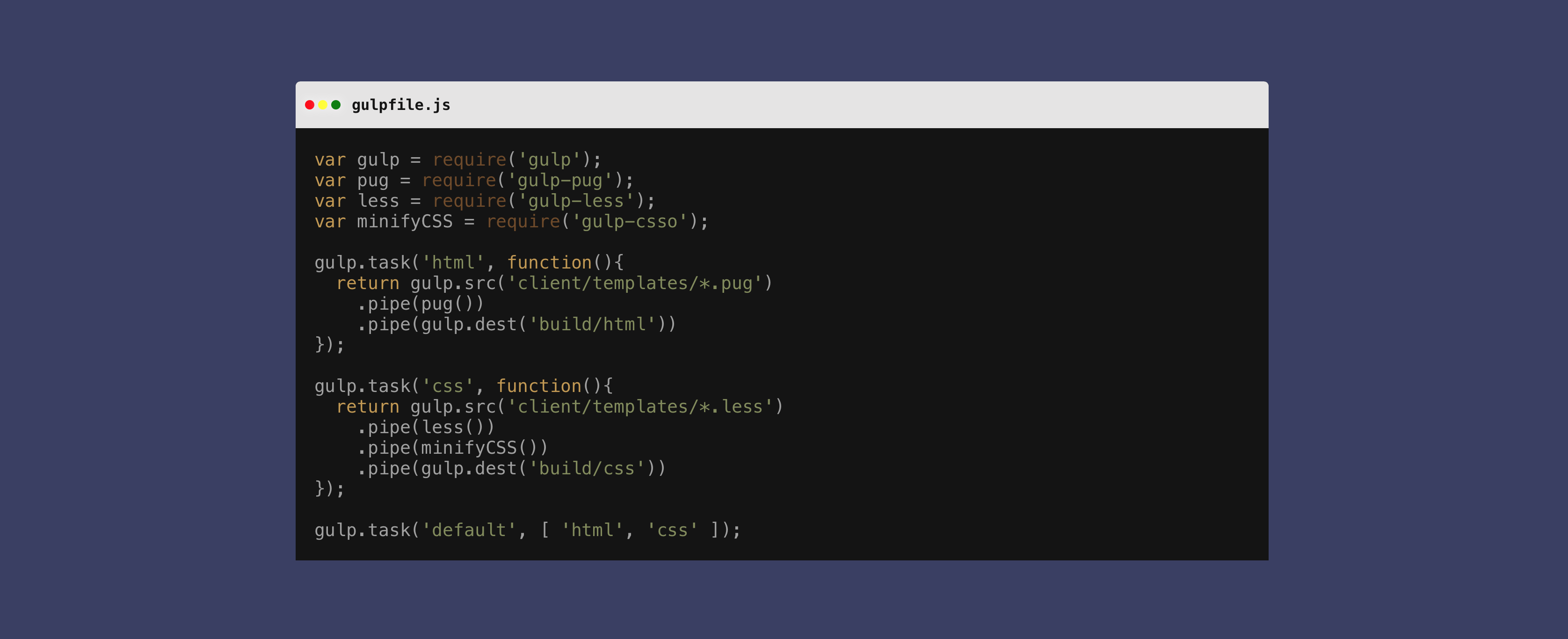
As I mentioned a few days ago, I’m using Gulp on a new WordPress project. I like to back up my work every night, and since a lot of WordPress config and customization happens in the WordPress editor and widgets, that means backing up the mysql database as well as the code.
Why not use this newfound tool? Let’s do it.
I did some searching and found Gulp WordPress Backup, but it was overkill for what I wanted. But I saw that it used an npm package named mysqldump, for the export, so I grabbed that and started setting up a new task in gulpfile.js:
// add mysqldump as a dependency var mysqlDump =require('mysqldump');// dumpDatabase gulp.task('dumpDatabase', () => { return new Promise((resolve,reject)=>{mysqlDump({host:'localhost',user:'user',password:'pass',database:'wp_database',dest:'backup.sql'},(err)=>{if(err!==null)returnreject(err);});}).catch((err)=>{console.log(err);});});
Next step: Defining the filename. I just wanted to use today’s date because I intend on running this at the end of each work day. Since gulp is all javascript, this is easy:
vartoday=newDate(),dd=today.getDate(),mm=today.getMonth()+1//January is 0! yyyy = today.getFullYear(); if(dd<10) { dd ='0'+dd}if(mm<10){mm='0'+mm}today=mm+'-'+dd+'-'+yyyy;
Add this to the gulp task and you are good to go!
gulp.task('dumpDatabase',()=>{vartoday=newDate(),dd=today.getDate(),mm=today.getMonth()+1//January is 0! yyyy =today.getFullYear();if(dd<10){dd='0'+dd}if(mm<10){mm='0'+mm}today=mm+'-'+dd+'-'+yyyy;returnnewPromise((resolve,reject)=>{mysqlDump({host:'localhost',user:'user',password:'pass',database:'wp_database',dest:'SQLBackups/'+today+'.sql'// Outputs to the folder named SQLBackups and uses today's date as the filename.},(err)=>{if(err!==null)returnreject(err);});}).catch((err)=>{console.log(err);});});
Make sure you add mysqldump to your project’s package.json, or at least run npm install mysqldump before using!
When I updated to macOS High Sierra, a bunch of necessary stuff broke: Jekyll, Homebrew, Node.js, and a bunch of gems. s3_website, the tool I use to deploy my Jekyll site to S3, was one of the gems that just completely disappeared. When I went to reinstall it, I got an error that I didn’t have Java installed. Against my better judgment, I went to the URL listed and installed it. Then I ran s3_website push.
After about 30 seconds, I got an error saying that s3_website doesn’t work with Java 9, which was the most recent version at the link. And also the version you get with brew cask install java. Well, shit.
Exception in thread "main" java.lang.ExceptionInInitializerError at org.jruby.Ruby.newInstance(Ruby.java:266) at s3.website.Ruby$.rubyRuntime$lzycompute(Ruby.scala:4) at s3.website.Ruby$.rubyRuntime(Ruby.scala:4) at s3.website.model.Config$$anonfun$15.apply(Config.scala:229) at s3.website.model.Config$$anonfun$15.apply(Config.scala:227) at scala.util.Try$.apply(Try.scala:192) at s3.website.model.Config$.erbEval(Config.scala:227) at s3.website.model.Site$$anonfun$2.apply(Site.scala:28) at s3.website.model.Site$$anonfun$2.apply(Site.scala:27) at scala.util.Success.flatMap(Try.scala:231) at s3.website.model.Site$.parseConfig(Site.scala:27) at s3.website.model.Site$.loadSite(Site.scala:100) at s3.website.Push$.push(Push.scala:62) at s3.website.Push$.main(Push.scala:40) at s3.website.Push.main(Push.scala) Caused by: java.lang.RuntimeException: unsupported Java version: 9 at org.jruby.RubyInstanceConfig.initGlobalJavaVersion(RubyInstanceConfig.java:1878) at org.jruby.RubyInstanceConfig.(RubyInstanceConfig.java:1585) ... 15 more
After lots of searching, I came across a kind soul on Github suggesting that we use jEnv to define which java environment to use in the directory.
When I first installed jenv, I couldn’t add versions to the tool. I kept getting this error:
ln: /usr/local/opt/jenv/versions/oracle64-9.0.1: No such file or directory
The line-height attribute doesn’t work on span by default. If you need to use line-height on a span, you’ll need to set display:block; on the span element to make it display as a block element (like
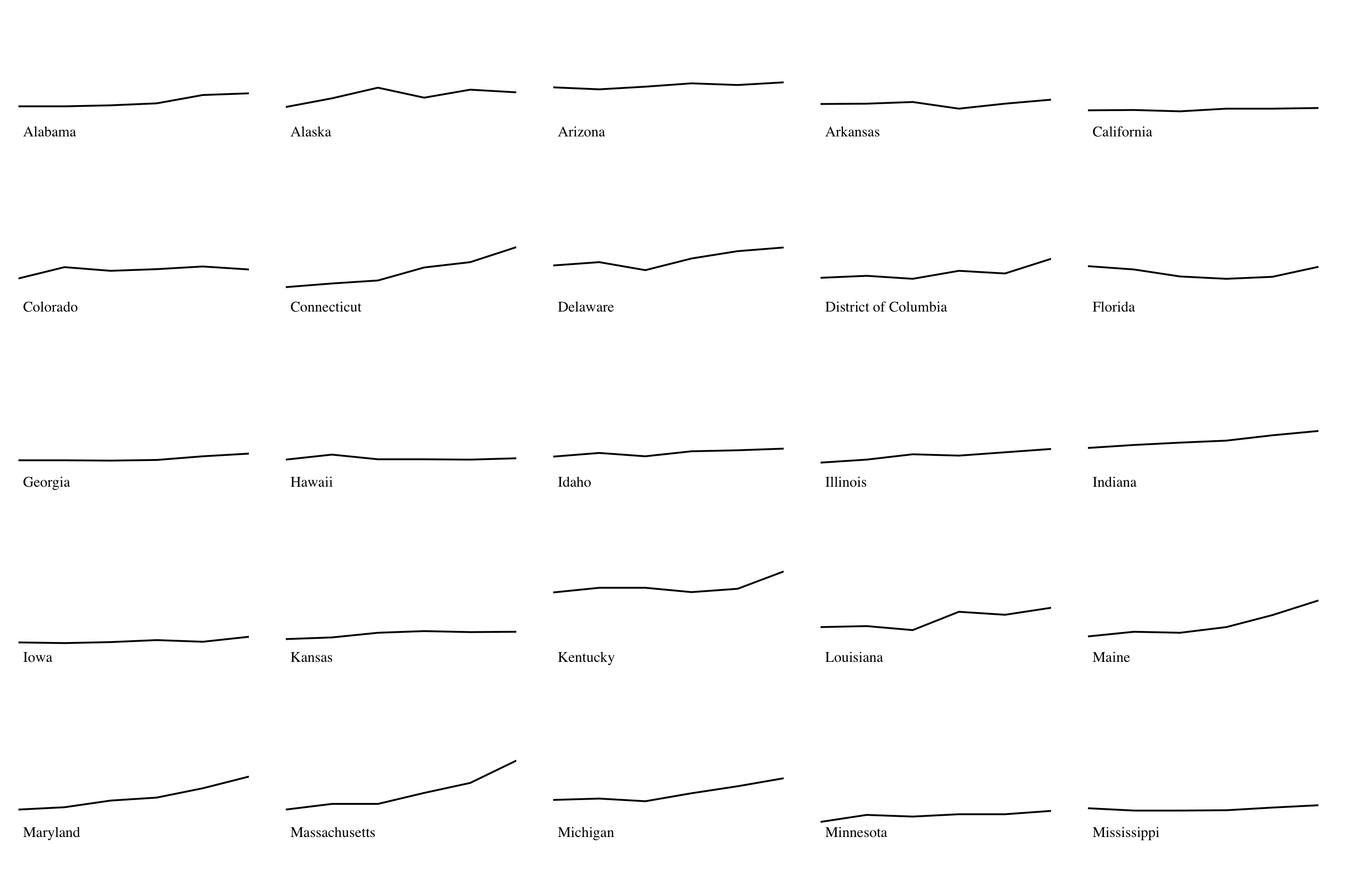
While working on the 51 Line Charts for my Opioid Crisis data visualization, I ran into an issue with generating all 51 charts at the same time: The data was either in 51 rows stacked and I couldn’t access the dates effectively, or 306 rows unstacked and I had 6x as many objects as I needed when I did a join.
The solution was to use D3.nest. Nesting allows elements in an array to be grouped into a hierarchical tree structure; think of it like the GROUP BY operator in SQL, except you can have multiple levels of grouping, and the resulting output is a tree rather than a flat table. The levels in the tree are specified by key functions.
When I used the state as a key, it grouped each state’s data together in a tree.
I’ve used Coda by Panic as my IDE of choice for 10 years now, but I think it is starting to fall behind other tools. It isn’t updated often and there aren’t nearly as many community-built packages as other tools have. So I’m giving both Atom and Sublime a try. I’m trying Atom first.
In my first few days of use, here are some things I love:
d3-snippets package – The D3 is super powerful, but unless you use it every day, it is easy to forget the syntax for its huge array of features. I usually need to keep the documentation open in another window. With this package I just need to start typing what I need and I get a list of options with useful snippets.
platformio-ide-terminal package – Yeah, opening terminal.app in another window is easy. But having everything in one place is great.
It is so easy to find and install new packages for Atom. And there are so many!
Git integration – I usually use the command line for git, but I love being able to see which files in the sidebar are new, modified, and staged. Then with the click of a button I can commit and push them.
Easy customization – Within seconds I was able to switch themes and default fonts.
Multi line editing. Protip: On a Mac go to System Preferences > Mission Control and turn off the Control + Shift + Up Arrow and Down Arrow keyboard commands, which you can then use in Atom for multi line selection and editing.
I’m working on a new WordPress theme development project and using Gulp and Sketch for the first time. Here are my first use notes:
Gulp
Toolkit for automating tasks. Tons of packages available for things like minifying JS, compiling Sass, linting, packaging into zip files, pushing content to S3 and external servers, watching and automatically rendering changes in the browser, etc.
Pain to install. Dependencies all the way down.
Everything important goes in gulpfile.js
Here are the tasks I’m using:
gulp styles — Compile, autoprefix and minify Sass files.
gulp scripts — Minify javascript files.
gulp images — Compress and optimize images.
gulp watch — Compile assets when file changes are made, start BrowserSync
gulp — Default task – runs all of the above tasks.
gulp zip — Package theme into zip file for distribution, ignoring node_modules.
Sketch
I love being able to take layers, merge them, and export them as different image formats. This makes exporting background content a breeze.
No longer do I need to toil with eyeballing buttons and trying to figure out their padding, background gradients, and border radius. Code export is a gift from above.
I like their price model. Use the app for life, free updates for a year, resubscribe when you need more updates.
Great email from Paul Jarvis’s Sunday Dispatches this week. The relationship doesn’t end once you make the sale. That is just the beginning. Don’t be the hot tub guy.
Sometimes I get off track. This is what I need to do to get back on track:
Turn off social media. Remove apps from phone, turn on the 1Blocker (iPad and iPhone) and WasteNoTime (Mac) rules.
Wash your face.
Drink a full glass of water and eat a healthy snack if you need one.
Get your keys and headphones, put on a podcast, go for a walk around the building. Breathe deeply the whole time. Check the mail when you come back in.
Clean off your desk, clean off the dining table, and empty/load the dish washer.
Turn off the podcast and turn on music (Jazz Vibes, Hundred Days Off, or Tycho). Sit down at the dining table with your notebook and make a list of the most important things that need to get one. Evaluate each item and block out a time on the calendar to knock it out over the next few days.
Pick one thing to start work on immediately. Start working.
Many people, database experts among them, dismiss Big Data as a fad that’s already come and gone, and argue that it was a meaningless term, and that relational databases can do everything NoSQL databases can. That’s not the point! The point of Big Data, pointed out by George Dyson, is that computing undergoes a fundamental phase shift when it crosses the Big Data threshold: when it is cheaper to store data than to decide what to do with it. The point of Big Data technologies is not to perversely use less powerful database paradigms, but to defer decision-making about data — how to model, structure, process, and analyze it — to when (and if) you need to, using the simplest storage technology that will do the job.A organization that chooses to store all its raw data, developing an eidetic corporate historical memory so to speak, creates informational potential and invests in its own future wisdom.
Next, there is machine learning. Here the connection is obvious. The more you have access to massive amounts of stored data, the more you can apply deep learning techniques to it (they really only work at sufficiently massive data scales) to extract more of the possible value represented by the information. I’m not quite sure what a literal Maxwell’s Historian might do with its history of stored molecule velocities, but I can think of plenty of ways to use more practical historical data.
And finally, there are blockchains. Again, database curmudgeons (what is it about these guys??) complain that distributed databases can do everything blockchains can, more cheaply, and that blockchains are just really awful, low-capacity, expensive distributed databases (pro-tip, anytime a curmudgeon makes an “X is just Y” statement, you should assume by default that the(X-Y) differences they are ignoring are the whole point of X). As with Big Data, they are missing the point. The essential feature of blockchains is not that they can poorly and expensively mimic the capabilities of distributed databases, but do so in a near-trustless decentralized way, with strong irreversibility and immutability properties.
Sometimes you have to stop what you are doing and climb out on the roof to take a #ManhattanSkyline photo because the sunset is so beautiful. #nofilter
A lot of email services track you by putting a tiny transparent image in your email and logging when you load it. You can prevent this by turning off autoloading of remote images in your favorite email app’s settings. If your app doesn’t have that setting, consider switching. I’m currently using Airmail across all of my devices and the setting is under Settings > Advanced.
One evening last week I had the idea to draw some quick sketches to illustrate some concepts in the Praxis curriculum. I used my iPad, Apple Pencil, Procreate, Paper by 53Archived Link, and Pixelmator.
Wes Anderson and his team are so good. Their attention to detail is extraordinary. Every single one of the dogs in this animation have a deep level of emotion and personality. I’m looking forward to seeing this in theaters next year.
This is a super cool short film documenting a series of art installations by Lucas Zanotto. Simple colors, shapes, and movements can convey so much emotion and character.
Like many, I’m all about that Inbox Zero life. I’m not going to preach here about it. You’ve heard enough of that elsewhere. I’m going to show you how I get it done.
Winning Before Starting
I like to set myself up for success whenever possible. What that looks like here is severely limiting the amount of inbound email I get. Fewer incoming messages means fewer messages to process.
I am ruthless about unsubscribing to unwanted emails. I am only subscribed to seven newsletters, all of which I get value out of regularly. I immediately unsubscribe from sales and marketing emails I get after buying stuff online. If I have to give an email address on a website, I add “+promo” to the end of my address and use a rule to automatically send it to the trash.
For important day-to-day questions and messages from coworkers, we use Slack.
These few things cut my email volume by 80%. The remaining 20% is primarily important, valuable, or actionable: Emails from clients, customers, friends, and family, important notifications, and interesting newsletters that I actually read.
Method
I primarily process email on my 10.5″ iPad Pro using Spark or Airmail. I switch back and forth between the two every few weeks. Emails I can respond to immediately, I do. Emails that need further action get added to my to-do list. Both have a key feature that is critical to my workflow: The Share Sheet. This allows me to take an email and put it as a to-do item in my favorite task manager with a few taps without switching apps. As soon as an email gets added to my task list, it gets archived. The task includes a link directly to the email so I can get back to it quickly if needed.
On my Mac I also use Spark and Airmail, switching to whichever one I’m using on my iPad at the time. Both have widgets that allow me to share the email to my favorite task manager.
I use Things 3 as my task manager. Tasks that I share from my email get put into a holding zone (also called the Inbox), which I process and assign a due date and put into the correct bucket twice a day. Things has my definitive task list and I use it as a launch pad for planning my day each morning.
Every Monday I set my plan for the week and send it over to my boss. Because I’m not dogmatic about maintaining Inbox Zero every single day, I clear it out on Monday mornings before organizing my task list for the week just in case something in my email needs to go on the list.
That is it. This is consistent for me because it is tied to a concrete weekly deliverable: My weekly check-in with Isaac. In order to give an accurate representation of my priorities and tasks for the week, I must clean out my inbox first. I leave myself no choice in the matter, because if I did, I’m likely to ignore my inbox and let it get out of hand.
We always focus on the downsides of super intelligent AI. There are, however, upsides. Super intelligence can help solve some of the biggest problems of our time: Safety, medical issues, justice, etc.
Containment is both a technical and a moral issue. Much more difficult than currently given credit for. Given ways we have to construct it, we likely can just “unplug” it.
Tegmark defines these three stages of life:
Life 1.0: Both hardware and software determined by evolution. (Flagella)
Life 2.0: Hardware determined by evolution, software can be learned (Humans)
Life 3.0: Both hardware and software can be changed at will. (AI machines)
Wide vs narrow intelligence: Humans have wide intelligence. Generally good a lot a lot of different tasks and can learn a lot implicitly. Computers have (so far) with narrow intelligence. They can calculate and do programmed tasks much better than us. But will completely fail at needing to account for unwritten constraints when someone says, “take me to the airport as fast as possible.”
The moment the top narrow intelligence gets knit together and meets the minimum of general intelligence, it will likely surpass human intelligence.
What makes us intelligent is the pattern in which the hardware is arranged. Not the building blocks themselves.
The software isn’t aware of the hardware. Our bodies are completely different from when we were young, but we feel like the same person.
The question of consciousness is key. A subjective experience depends on it.
We probably already have the hardware to get human-level general intelligence. What we are missing is the software. It is unlikely to be the same architecture as the human brain, likely similar. (Planes are much more simple than birds.)
AI Safety research needs to go hand-in-hand with AI research. How do we make computers unhackable? How do we contain it in development? How do we ensure system stability?
One further issue you are going to need to overcome is having computers answer how a decision was made in an understandable way instead of just dumping a stack trace.
Tegmark councils his own kids to go into fields that computers are bad at. Fields where people pay a premium for them to be done by Humans.
“It’ll-get-worse-before-it-gets-better” fallacy: A variant of confirmation bias. If the problem gets worse, the prediction is confirmed. If the situation improves unexpectedly, the customer is happy and the expert attributes it to his prowess. Look for verifiable cause-and-effect evidence instead.
Story bias: We tend to interpret things with meaning, especially things that seem connected. Stories are more interesting than details. Our lives are mostly series of unconnected, unplanned events and experiences. Looking at these ex post facto and making up an overarching narrative is disingenuous. The problem with stories is that they give us a false sense of understanding, which leads us to take bigger risks and urges us to take a stroll on thin ice. Whenever you hear a story, ask: Who is the sender, what are his intentions, and what does this story leave out or gloss over?
Hindsight bias: Possibly a variant on story bias. In retrospect, everything seems clear and inevitable. It makes us think we are better predictors than we actually are, causing us to be arrogant about our knowledge and take too much risk. To combat this, read diaries, listen to oral histories, and read news stories from the time you are looking at. Check out predictions from the time. And keep your own journal with your own predictions about your life, career, and current events. Compare them later to what happened to see how poor of a predictor we all are.
Overconfidence effect: We systematically overestimate and our ability to predict on a massive scale. The difference between what we know and what we think we know is huge. Be aware that you tend to overestimate your knowledge. Be skeptical of predictions, especially from so-called experts. With all plans, favor the pessimistic scenario.
Chauffeur Knowledge: There are two types of knowledge: Real knowledge (deep, nuanced understanding) and Chauffeur knowledge (enough knowledge to put on a show, but understanding to answer questions or make connections). Distinguishing between the two is difficult if you don’t understand the topics yourself. One method is the circle of competence. True experts understand the limits of their competence: The perimeter of what they do and do not know. They are more likely to say “I don’t know.” The chauffeurs are unlikely to do this.
Illusion of Control: Similar to placebo effect. The tendency to believe that we can influence something over which we have absolutely no sway. Sports, gambling, etc. Also: Elevators, cross walks, fake temperature dials. This illusion led prisoners (like Frankel, Solzhenitsyn, etc) to not give up hope in concentration camps. Federal reserve’s federal funds rate is probably a fake dial, too. The world is mostly an uncontrollable system at the level we currently understand it. The things we can influence are very few.
Incentive Super-Response Tendency: People respond to incentives by doing whatever is in their best interest. Extreme examples: Hanoi rats being bred, Dead Sea scrolls being torn apart. Good incentive systems take into account both intent and reward. Poor incentive systems often overlook and even corrupt the underlying aim. “Never ask a barber if you need a haircut.” Try to ascertain what actions are incentivized in any situation.
Regression to Mean: A cousin of the “It’ll-get-worse-before-it-gets-better” and the Illusion of Control fallacies. Extreme performances are often interspersed with less extreme ones. There are natural variations in performance. Students are rarely always high or low performers. They cluster around the mean. Thinking we can influence these high and low performers is an illusion of control.
Outcome Bias: We tend to evaluate decisions based on the result rather than the decision process. This is a variant on the Hindsight Bias. Only in retrospect do signals seem clear. When samples are too small, the results are meaningless. A bad result does not necessary indicate a bad decision and vice versa. Focus on the reasons behind actions: Were they rational and understandable?
Paradox of Choice: A large selection leads to inner paralysis and also poorer decisions. Think about what you want before inspecting existing offers. Write down the criteria and stick to them rigidly. There are never perfect decisions. Learn to love a good choice.
Liking Bias: The more we like someone, the more we are inclined to but from or help that person. We see people as pleasant if (a) they are outwardly attractive, (b) they are similar to you, or (3) they like you. This is why the salesperson copies body language and why multi-level marketing schemes work. Advertising employs likable figures in ads. If you are a salesperson, make people like you. If you are a consumer, judge the product independent of the seller and pretend you don’t like the seller.
Endowment effect: We consider things to be more valuable the moment we own them. If we are selling something, we charge more than we ourselves would spend on it. We are better at holding on to things than getting rid of them. This effect works on auction participants, too, which drives up bidding. And late-stage interview rejections. Don’t cling to things, rather view them as the universe temporarily bestowing them to you.